Fibers
Fibers are also called M:N Threading, because M tasks will run on N OS
threads. Other names: green threads, stackful coroutines.
Green threads are all about moving the responsibility of managing threads from the kernel to user space. To do that, some kind of runtime needs to implement the functionality of a scheduler. Kernel’s scheduler switches between different threads, allowing each one to run its steps. The same thing needs to be done by the runtime now. Additionally, each task needs its own stack, and our runtime needs to load appropriate stacks between task switches. Normally, stack has a fixed size, fibers however often have dynamic/growable stacks.
Green threads cannot use blocking I/O operations, since they would block the entire process (assuming we’re using 1 native thread).
Implementation
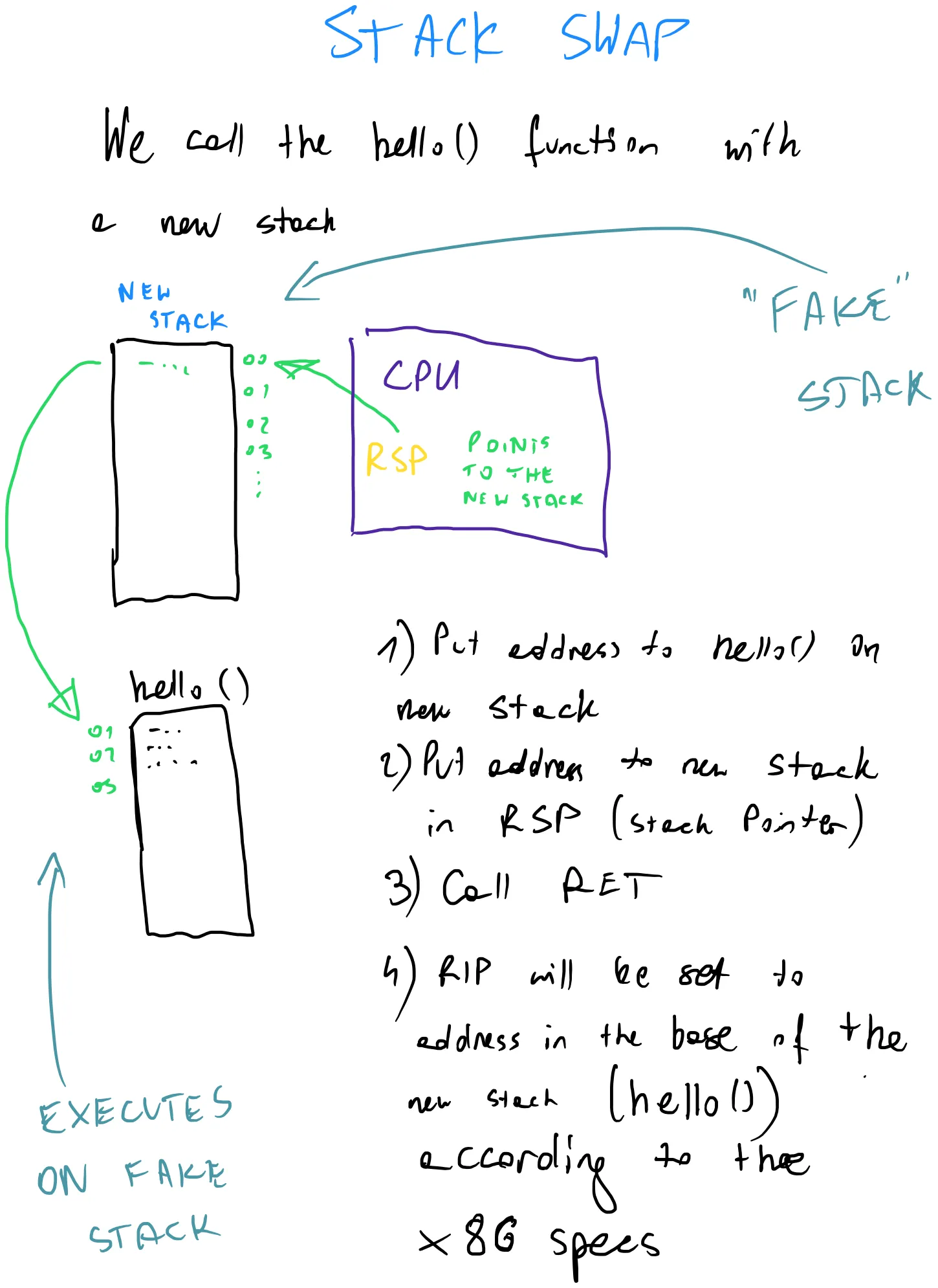
To implement fibers, we need some way of modifying the Program Counter register.
This is necessary for our scheduler to be able to switch between different
tasks. Processes cannot write to that register, but with a bit of assembler
trickery, we’re able to set PC to our desired address via the RET instruction.
When switching to a different task, we also need to switch the stack pointer to
the stack that belong to the new task.
This is a very simplified view on the matter. While switching the tasks, we also need to switch the registers state. The switching process must do pretty much the same context switch as the OS does when switching native threads.
Our runtime must also keep track of the state of each green thread. In the simplest case, a thread might be:
- available - thread awaiting for some code to run.
- running - the active thread
- ready - the task has some code to execute, and it’s awaiting for scheduler to let it continue to run.
The simplest scheduler implementation might look like this:
#[inline(never)]fn t_yield(&mut self) -> bool { let mut pos = self.current; while self.threads[pos].state != State::Ready { pos += 1; if pos == self.threads.len() { pos = 0; } if pos == self.current { return false; } }
if self.threads[self.current].state != State::Available { self.threads[self.current].state = State::Ready; }
self.threads[pos].state = State::Running; let old_pos = self.current; self.current = pos;
unsafe { let old: *mut ThreadContext = &mut self.threads[old_pos].ctx; let new: *const ThreadContext = &self.threads[pos].ctx; asm!("call switch", in("rdi") old, in("rsi") new, clobber_abi("C")); } self.threads.len() > 0}The actual switch will have to prepare the registers for the new task to run:
#[naked]#[no_mangle]unsafe fn switch() { asm!( "mov 0x00[rdi], rsp", "mov 0x08[rdi], r15", "mov 0x10[rdi], r14", "mov 0x18[rdi], r13", "mov 0x20[rdi], r12", "mov 0x28[rdi], rbx", "mov 0x30[rdi], rbp", "mov rsp, 0x00[rsi]", "mov r15, 0x08[rsi]", "mov r14, 0x10[rsi]", "mov r13, 0x18[rsi]", "mov r12, 0x20[rsi]", "mov rbx, 0x28[rsi]", "mov rbp, 0x30[rsi]", "mov rdi, 0x38[rsi]", "ret", options(noreturn) );}Here, we can see an example of how to use fibers from the client side:
fn main() { let mut runtime = Runtime::new(); runtime.init();
runtime.spawn(|| { println!("THREAD 1 STARTING"); let id = 1; for i in 0..10 { println!("thread: {} counter: {}", id, i); yield_thread(); } println!("THREAD 1 FINISHED"); });
runtime.spawn(|| { println!("THREAD 2 STARTING"); let id = 2; for i in 0..15 { println!("thread: {} counter: {}", id, i); yield_thread(); } println!("THREAD 2 FINISHED"); }); runtime.run();}We can see that this implementation is cooperative. Threads need to call
yield_thread() for other thread to be scheduled. Normally, the runtime should
provide libraries that yield whenever some I/O request is made. Then, using
event queues, the runtime can be notified when the thread
should be marked as ready to continue to run (because some I/O operation is
finalized).
spawn will setup some available thread with proper context, and mark it as Ready.
The scheduler (shown above) will switch to that thread at some point.
pub fn spawn(&mut self, f: fn()) { let available = self .threads .iter_mut() .find(|t| t.state == State::Available) .expect("no available thread.");
let size = available.stack.len();
unsafe { let s_ptr = available.stack.as_mut_ptr().offset(size as isize); let s_ptr = (s_ptr as usize & !15) as *mut u8; std::ptr::write(s_ptr.offset(-16) as *mut u64, guard as u64); std::ptr::write(s_ptr.offset(-24) as *mut u64, skip as u64); std::ptr::write(s_ptr.offset(-32) as *mut u64, f as u64); available.ctx.rsp = s_ptr.offset(-32) as u64; } available.state = State::Ready;}Summary
We can see that applications making use of green threading require some sorts of a runtime. That changes the model of how our code runs (compared to simplest compiled environments). Our program becomes kind of hosted within a runtime, which switches between threads in the background. For our program, the only thing that it “sees” is how it needs to yield control sometimes. Without deeper thought, we could even assume that those yields are pretty much the same thing as kernel doing preemption.
More genearally, I think we can list the following abstractions:
- embedded programming (think microcontrollers) - our programs truly run on bare metal. Of course, it is still some simplification, but our code has full control of the CPU
- OS-based systems - our programs are hosted within the OS, and kernel has control over the CPU. Our program cannot run without kernel’s “permission”. The kernel has to allow our programto run by scheduling its process/threads on some available CPU cores
- green threads - we’re moving even higher up. Not only the kernel controls when our process can execute, but additionally, within that process, there’s a thin layer (some runtime), which switches between our green threads.
The list above is not any official or formal categorization of how programs run. This is just a summary of how we can look at green threading in terms of abstraction and complexity that it introduces.